
Building a Real-Time Web Events Pipeline with Kafka and Python
Recently, I built a real-time data pipeline to see how kafka was working practically. In this project, the concept of kafka broker, topic, producer, consumer are being shown. Before diving into the steps to follow, let’s first setup our environment.
Quick Setup
First, we will need to use Docker to install kafka and all the needed dependencies, this helps to ensure we encapsulate the tools we need and isolate it from our global system. Then, we will need to install Python.
Docker Configuration
Create a docker-compose.yml file:
version: "3"
services:
zookeeper:
image: confluentinc/cp-zookeeper:latest
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
ports:
- 22181:2181
kafka:
image: confluentinc/cp-kafka:latest
depends_on:
- zookeeper
ports:
- 9092:9092
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://localhost:9092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
The docker file contains 2 services: zookeeper and kafka
- Zookeeper is needed for Kafka to work because zookeeper is what we call a distributed coordination service, it ensures the latest works as per expected given its supervisor role, we will discuss about this specific in another article
- Kafka obviously since it’s the core technology we are testing out
Start everything with:
docker compose up -d
Python Dependencies
Then, following the same idea with the docker container to isolate our dev environment, we will create and activate a virtual environment:
python3 -m venv kafka-env
source kafka-env/bin/activate
Then install the required package:
pip install kafka-python
That’s all we need to get started
Creating the Kafka Infrastructure
Ok now we will create a topic to store web events:
docker compose exec kafka kafka-topics --create \
--topic web-events \
--bootstrap-server localhost:9092 \
--partitions 1 \
--replication-factor 1
Breaking down each parameter:
docker compose exec kafka- We execute a command inside the Kafka containerkafka-topics --create- This uses Kafka’s topic management tool to create a new topic--topic web-events- We name our topic “web-events” (where all events will be stored)--bootstrap-server localhost:9092- We connects to the Kafka broker on port 9092--partitions 1- We create a single partition (keeping it simple for development)--replication-factor 1- We don’t have replication since we’re running a single broker
This creates a web-events topic where all user interactions will be stored. Think of it as a dedicated stream for your event data.
Monitoring Events in Real-Time
To see events as they flow through the topic, we will need to run this command:
docker compose exec kafka kafka-console-consumer \
--bootstrap-server localhost:9092 \
--topic web-events \
--from-beginning
What each part does:
kafka-console-consumer- This is a Built-in Kafka tool for reading messages from topics--bootstrap-server localhost:9092- This connect to our Kafka broker--topic web-events- This specifies which topic to read from--from-beginning- This reads all messages from the start (not just new ones)
We will need to keep this running in a terminal - we will see events appear as they’re being produced by our producer
The Producer: Generating Web Events
In the screenshot below, this is our python producer that simulates realistic web traffic:
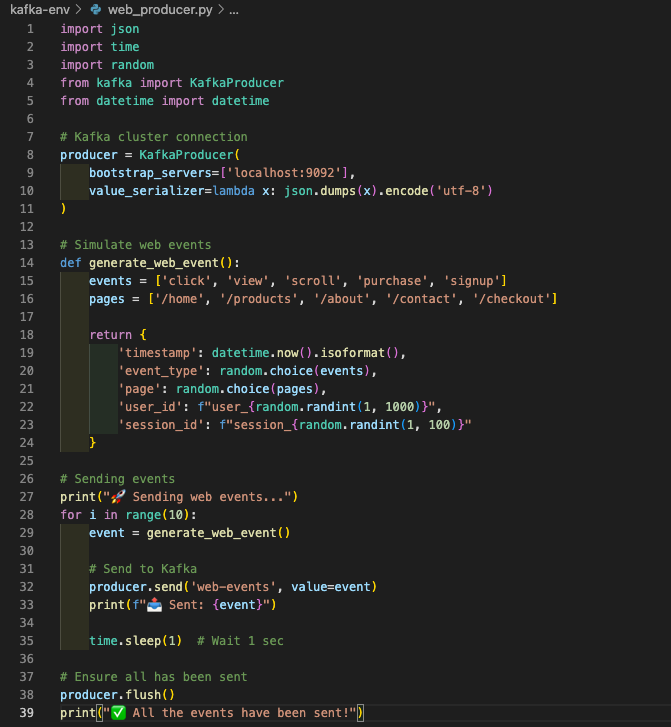
Run it with:
python3 web_producer.py
This script generates different types of events (page views, clicks, purchases) with realistic data as we would expect from a user on a website selling stuffs. Each event includes user information, timestamps, and relevant metadata.
See it in action:
What you’re seeing: The producer (right window) generates web events every few seconds - user clicks, page views, purchases. The left window shows the Kafka topic receiving and storing these events as JSON data.
This simulates what happens millions of times per day on platforms like Amazon or Facebook - user actions being captured and streamed for real-time processing.
The Consumer: Processing Events
Now let’s build a consumer to process these events in real-time:
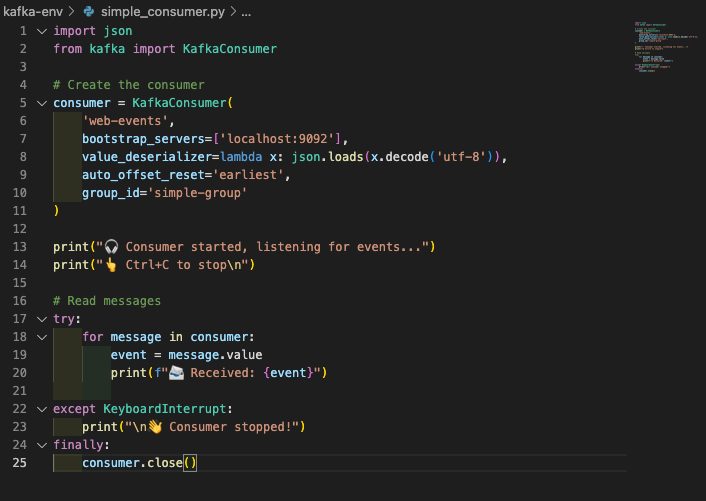
Run it with:
python3 simple_consumer.py
The consumer continuously reads from the Kafka topic and processes each event. In production, this would update databases, trigger notifications, or feed analytics systems.
Consumer in action:
What you’re observing: The consumer (lower right window) is reading events from our web-events topic (left terminal window) which had been fed data by our producer script (upper right window). Each event is parsed and could trigger various business logic - updating user sessions, calculating metrics, or feeding real-time dashboards.
Why This Architecture Works
This event-driven approach offers several advantages:
- Scalability: Add more consumers to handle increased load without changing the producer
- Reliability: Kafka persists events, so consumers can recover from failures
- Flexibility: Multiple consumers can process the same events for different purposes
- Real-time processing: Events are handled immediately, not in batches
Practical Applications
With this basic pipeline, you can build:
- Real-time analytics dashboards
- User activity tracking systems
- Event-driven microservices
- Recommendation engines
- Fraud detection systems
The same pattern scales from hobby projects to enterprise systems handling millions of events per second.
Conclusion
This pipeline demonstrates the core concepts behind modern event-driven architectures, though this pipeline’s simulation only handles few requests, the idea was to show how it works through a lab. It was interesting to see the interaction of the producer-kafka broker-consumer.
