
Understanding Kafka Cluster Membership: How Brokers Join and Leave the Cluster
In this article, I want to show how does Zookeeper keeps track of broker registering, leaving by leveraging the logs.
The complete code scripts are available on my GitHub repository.
We will see how the first broker is set as being the Controller and also see how the partition leadership is being operated.
First step
The first command we have to run is docker compose up -d which will launch our zookeeper service and our 3 kafka brokers.
Controller election
When launching our services, intituively we could think broker 1 will be the controller.
In fact, this is not the case.
Looking at the respective kafka broker logs, we see that it is all about the broker who first successfully creates the zookeeper node (znode): you are right, this is a race!
broker 3 log:
[2025-07-17 18:14:11,261] INFO [Controller id=3] 3 successfully elected as the controller.Epoch incremented to 1 and epoch zk version is now 1 (kafka.controller.KafkaController)
broker 1 log:
[2025-07-17 18:14:11,277] DEBUG [Controller id=1] Broker 3 was elected as controller instead of broker 1 (kafka.controller.KafkaController)
broker 2 log:
[2025-07-17 18:14:11,300] DEBUG [Controller id=2] Broker 3 was elected as controller instead of broker 2 (kafka.controller.KafkaController)
We can see it only was a matter of milliseconds (ms):
- broker 3 created the znode at 18:14:11,261
- broker 1 tried to create it at 18:14:11,277
- broker 2 tried to create it at 18:14:11,300
This is also verified on the /controller namespace on zookeeper
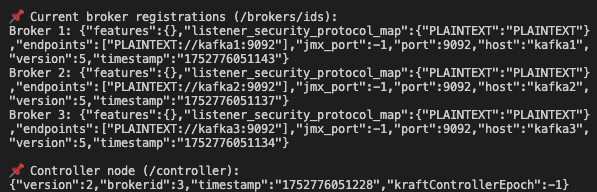
Partition leadership
On the docker compose file, set the variable KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR to 3 to ensure availability.
Step 1: Create a topic with replication=3, partition=3
then, run this command to create my-test-topic with a replication-factor of 3 to ensure each partition of the kafka topic will be replicated to 3 brokers.
partitions of 3 means that the topic’s data will be split in 3 separate partition who will be distributed to brokers evenly. Since we have 3 brokers and 3 partitions, each broker will have 1 partition.
docker exec -it 07-kafka-internals-cluster-membership-kafka1-1 kafka-topics --create \
--bootstrap-server kafka1:9092 \
--replication-factor 3 \
--partitions 3 \
--topic my-test-topic
Step 2: View partition leadership
docker exec -it 07-kafka-internals-cluster-membership-kafka1-1 kafka-topics --describe \
--bootstrap-server kafka1:9092 \
--topic my-test-topic

This means:
- Partition 0 is led by broker 3.
- Partition 1 is led by broker 1.
- Partition 2 is led by broker 2.
Let’s break down the first line to ensure we understand what happened:
Topic: my-test-topic Partition: 0
Leader: 3
Replicas: 3,1,2
Isr: 3,1,2
- Topic: my-test-topic
- Partition: 0 — this is one of the partitions of the topic
- Leader: 3 — Broker 3 is currently the leader for partition 0:
- Producers send data to this broker for this partition
- Consumers read from this broker for this partition
If broker 3 fails, leadership will move to broker 1 or 2.
Replicas: 3,1,2 — All three brokers store a copy of partition 0:
- Broker 3 (leader)
- Broker 1 (follower)
- Broker 2 (follower)
ISR (In-Sync Replicas): 3,1,2 — All replicas are up-to-date with the leader.
Simulation of a kafka broker failure
docker exec -it 07-kafka-internals-cluster-membership-kafka1-1 \
/usr/bin/kafka-topics \
--bootstrap-server kafka1:9092 \
--describe --topic my-test-topic
Stop broker 2
docker stop 07-kafka-internals-cluster-membership-kafka2-1
When we run --describe again

We can see partition leadership reassignment here as broker 2 was the leader of partition 2. Now, since broker 2 has been shut down, the partition 2’s leader has been assigned to broker 3.
Note:
-
The broker 2 still appear in the Replica because broker was assigned as one of the replicas
-
The ISR did remove broker 2 as it is now down or out-of-sync (here down), so it is not in the ISR
Conclusion
In this hands-on, we’ve tested a common real-world scenario: broker failure and how Kafka handles partition leadership reassignment in response. This kind of failure is frequent in production environments and understanding how Kafka maintains availability and consistency is critical. In future experiments, we’ll explore deeper production-grade scenarios such as controller failover, under-replicated partitions, rolling broker restarts, and consumer resilience to give a more complete view of Kafka’s fault-tolerance mechanisms
